Este ejercicio está diseñado para mostrar cómo PCA puede simplificar y clarificar datos complejos, facilitando el análisis y la interpretación de resultados.
Podéis consultar el desarrollo del análisis, y conclusiones aquí:
(2) https://github.com/acastromartinez/GITHUB—R
![]() En este caso utilizo el dataset «biopsy» del paquete MASS, uno de los más populares y ampliamente utilizados en análisis estadístico. Fue desarrollado por el grupo de Venables y Ripley, y acompaña el libro «Modern Applied Statistics with S».
En este caso utilizo el dataset «biopsy» del paquete MASS, uno de los más populares y ampliamente utilizados en análisis estadístico. Fue desarrollado por el grupo de Venables y Ripley, y acompaña el libro «Modern Applied Statistics with S».
![]() El conjunto de datos «biopsy» contiene información para la clasificación de tumores mamarios en <benignos> o <malignos> según características obtenidas a partir de imágenes de biopsias por aspiración con aguja fina, en masas mamarias. Los datos incluyen tanto características cuantitativas de las células como la clasificación final del tumor. Es un dataset pequeño y manejable que ofrece diversidad de características para aplicar múltiples técnicas de modelado y, es ideal para enseñar y experimentar con análisis de datos y machine learning. Además, está bien documentado y soportado en el paquete MASS de R.
El conjunto de datos «biopsy» contiene información para la clasificación de tumores mamarios en <benignos> o <malignos> según características obtenidas a partir de imágenes de biopsias por aspiración con aguja fina, en masas mamarias. Los datos incluyen tanto características cuantitativas de las células como la clasificación final del tumor. Es un dataset pequeño y manejable que ofrece diversidad de características para aplicar múltiples técnicas de modelado y, es ideal para enseñar y experimentar con análisis de datos y machine learning. Además, está bien documentado y soportado en el paquete MASS de R.
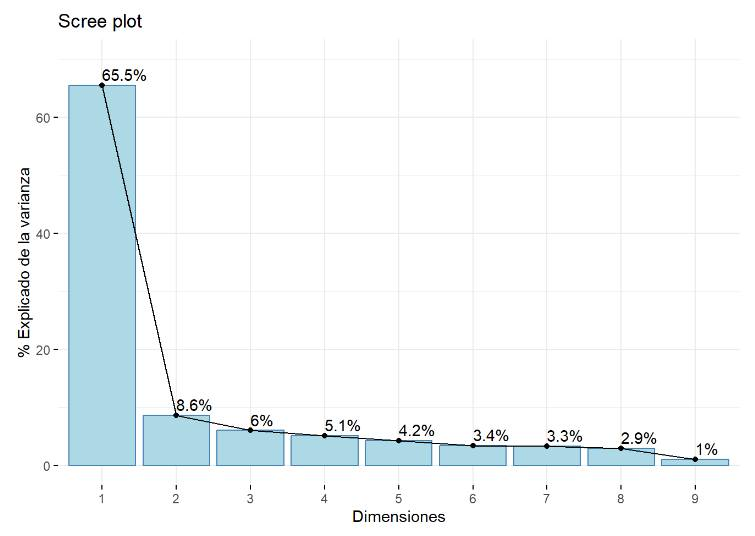
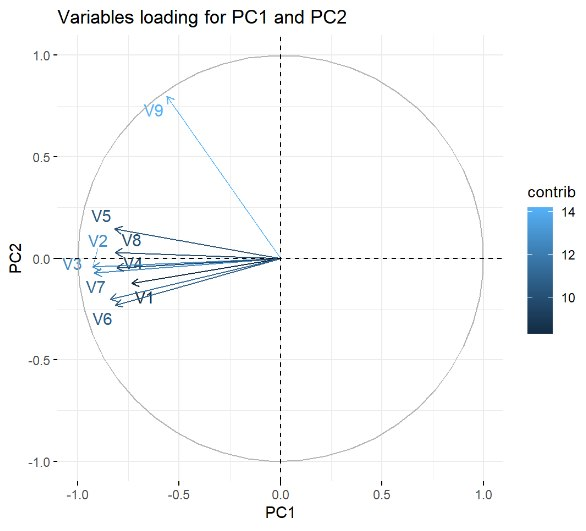
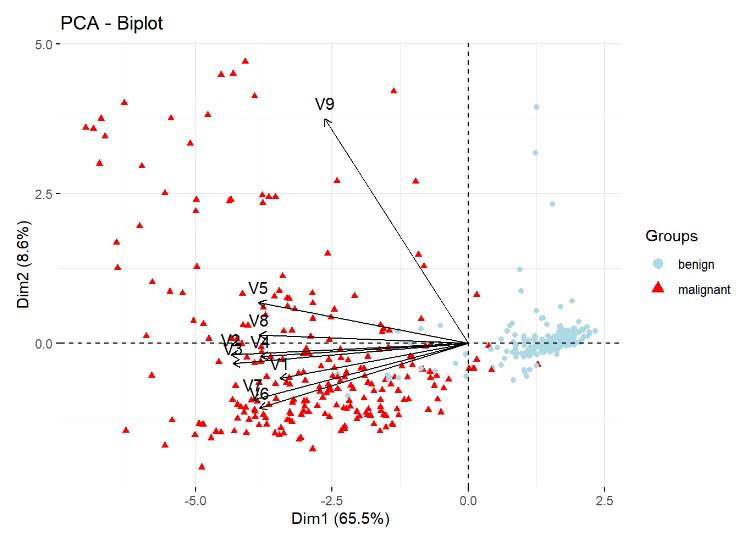
![]() PCA simplifica el análisis y mejora la visualización e interpretación de los resultados al transformar las variables originales en un nuevo conjunto de componentes principales o factores. Estos componentes retienen la mayor cantidad de información posible, utilizando menos dimensiones. Así, el primer componente principal explica la mayor parte de la varianza en los datos, mientras que cada componente subsiguiente captura la mayor cantidad de varianza restante sin redundar en la información ya explicada por los componentes anteriores. El PCA es particularmente valioso para grandes conjuntos de datos, ya que permite una simplificación significativa del análisis y una visualización efectiva, sin sacrificar la información relevante.
PCA simplifica el análisis y mejora la visualización e interpretación de los resultados al transformar las variables originales en un nuevo conjunto de componentes principales o factores. Estos componentes retienen la mayor cantidad de información posible, utilizando menos dimensiones. Así, el primer componente principal explica la mayor parte de la varianza en los datos, mientras que cada componente subsiguiente captura la mayor cantidad de varianza restante sin redundar en la información ya explicada por los componentes anteriores. El PCA es particularmente valioso para grandes conjuntos de datos, ya que permite una simplificación significativa del análisis y una visualización efectiva, sin sacrificar la información relevante.
Este ejercicio no solo demuestra la potencia de PCA en el análisis de datos biomédicos, sino que también sirve como un recurso para quienes están aprendiendo técnicas de análisis multivariante en R. Espero que os resulte de interés, si fuera el caso.