En este proyecto nos vamos a centrar en la aplicación de técnicas de análisis de datos para investigar los precios de mercado de los automóviles usados, utilizando el icónico modelo Mazda MX-5 como caso de estudio específico. Conocido por su diseño deportivo y características de conducción, este vehículo me ha resultado interesante debido a su popularidad y la variedad de variables que pueden afectar a su valor en el mercado de vehículos usados.
*** En la situación actual, el análisis de datos se ha convertido en una herramienta fundamental para entender el mercado y tomar decisiones informadas. En particular, estudiar los precios en el mercado de automóviles usados proporciona un medio único para investigar tendencias, patrones y factores que influyen en la dinámica del sector automotriz.
Se obtuvieron datos de varios sitios web especializados en venta de automóviles usados (Febrero, 2024). Estos fueron recopilados y procesados para crear un documento Excel optimizado desde el origen para facilitar los análisis posteriores. Se prestó especial atención a la calidad y coherencia de los datos para garantizar su utilidad a la hora de obtener conclusiones fiables. El análisis de los datos recopilados se realizó utilizando el lenguaje de programación R, conocido por su robustez y versatilidad en el análisis de datos. R proporciona una amplia gama de herramientas estadísticas y paquetes especializados que permiten un análisis avanzado y, una visualización clara de los resultados.

En la imagen podéis ver un ejemplo de las primeras líneas del documento creado a partir de los datos obtenidos en páginas web de mercado de segunda mano de vehículos. El total de filas del documento es de 162.
CÓDIGO COMENTADO

Utilizamos en este trabajo las librerías tidyverse, ggplot2, readxl y hrbrthemes. Creo el dataframe «data» a partir de los datos que tenemos en el excell mediante la función read_xlsx. Con la función names() podemos ver el nombre de las variables y, como se hace en este caso, con <- asignarles nuevos nombres.
Existe la posibilidad de que, introduciendo los datos de los anuncios de venta, repitamos alguno de ellos. Hay coches que se venden en diferentes páginas de venta de segunda mano, con los mismos datos de kms, precio, etc. Para eliminar los duplicados (durante una fase posterior de data cleaning), creé una variable a la que llamé price_km, calculada como la relación entre las variables price_eur (precio en euros) y kms (kilómetros). La finalidad de esto es utilizarla para eliminar filas duplicadas. Se podría haber hecho de otra forma, pero para este caso lo hice así, considerando como duplicadas aquellas filas que tenían el mismo valor de price_km.
Cuando quiero incluir nuevos datos solo tengo que meterlos en el documento de excell y volver a pasar el fichero por el script de R.

Mediante la función group_by y, posteriormente, summarise obtengo el número de vehículos y los precios medios, mínimos y máximos para cada modelo de MX5 considerado en la variable «model». La parte del código na.rm = TRUE sirve para indicar que los valores NA que se encontraran en el dataset han de eliminarse (NA.remove). *** El Mazda MX5, también conocido como MIATA, ha pasado por 4 generaciones desde que hizo su aparición en 1989. Los códigos NA, NB, NC y ND hacen referencia a cada una de estas generaciones, ordenados desde el más antiguo al más actual. Para este ejemplo y, por decisión personal, consideré únicamente que la variable «model» tuviera 3 categorías. Concretamente: NA, NB-NC y ND.
La función mutate nos permite crear una nueva variable «uds%«, con el porcentaje de unidades (coches) de cada modelo considerado (NA, NB-NC, ND). Round sirve para redondear las cifras a los 5 decimales indicados. La función arrange nos permite ordenar los resultados de forma descendiente según la media de los precios de los modelos (del más caro, al más barato). Utilizo sum para sumar los porcentajes y comprobar que la nueva variable tiene valores correctos, al dar 100%. El resultado de todos estos procesos aplicados está guardado en miata_price_model.

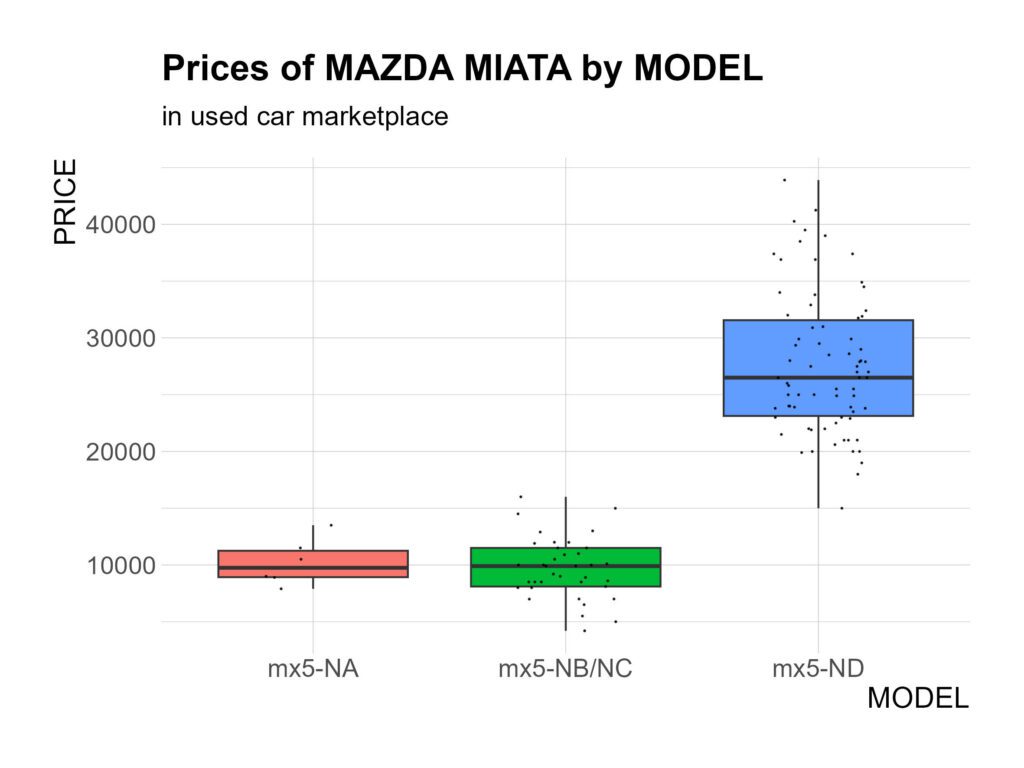
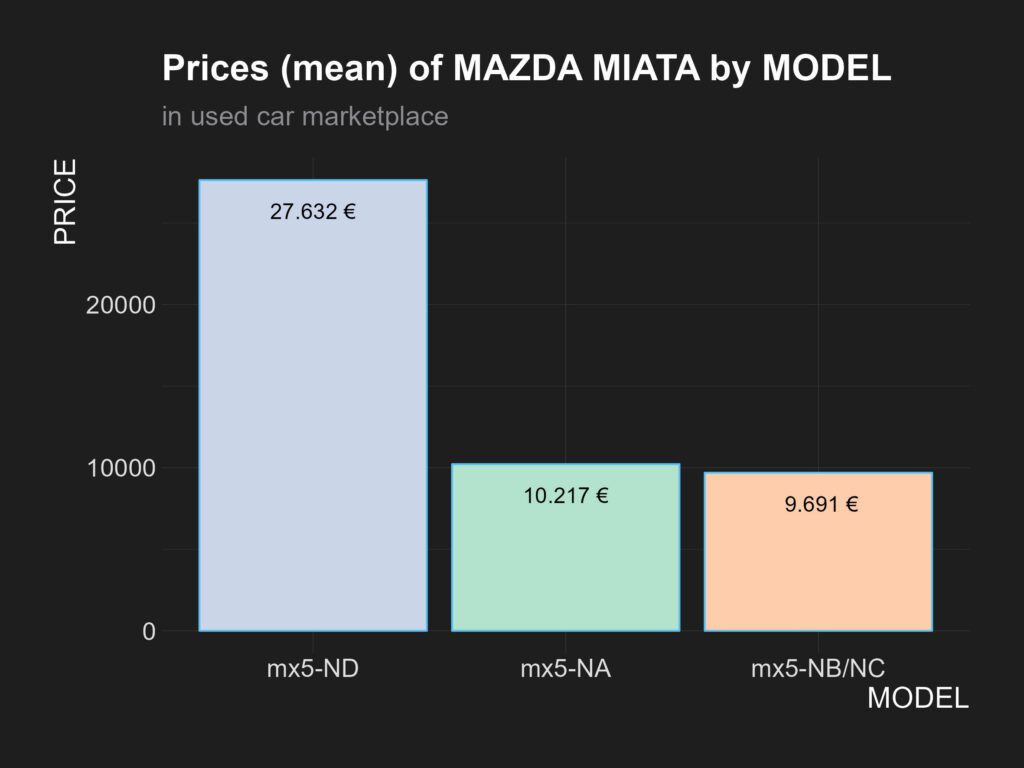
En un primer vistazo podemos observar que tenemos un mayor número de registros para el modelo de la última generación ND, con 74 observaciones (63,2%) y, solo 6 para el más antiguo NA. Los coches del modelo ND son los que tienen tienen el mayor precio en el mercado, con un precio medio de 27.632 euros y, un máximo que alcanza los 43.900 euros.
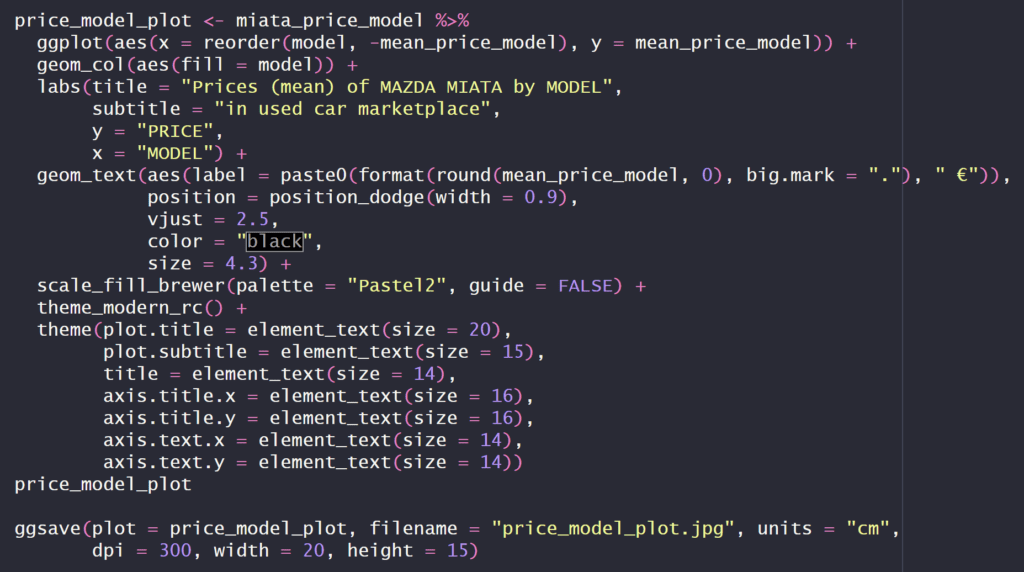
🖍️Código y VIZ de gráfico de barras con el precio medio de cada una de las categorías de modelos de los Mazda MX5 anunciados en el mercado de coches de segunda mano (FEBRERO, 2024). Utilizamos la librería ggplot y el «tema» theme_modern_rc de la librería hrbrthemes que cargamos al inicio del proyecto. Por último, guardamos el gráfico con la función ggsave.
🖍️Código y gráfico Boxplot. En este caso utilizamos theme_ipsum para el aspecto general, uno de los temas que más me gustan y suelo usar en los vizs. Con la función ggsave podemos controlar parámetros como el tamaño (ancho y alto) o la resolución (dpi) de la imagen.